

NTT 算子
GPU 进行 NTT 连续访存,需要将标量转变为列主序 (Column-Major Layout)形式
1.对于NTT 前n-2轮 跨度不会超过$2^{n-3}$ 那么就用四张卡独立的去算前n-2轮
2 .四张卡之间需要 进行一次数据交换,每张卡需要与另外三张卡各交换的 1 2 𝑛−2个标量,来消除卡 与卡间数据依赖问题。交换完成后,每张卡仍然拥有2 𝑛−2个标量。
1.不同 GPU 拓扑结构下数据传输优化
Nvlink 全连接拓扑 直接卡与卡直接直接传输即可
Nvlink 环路链接拓扑 需要两个交换,将数据分为两部分走两次
2.卡内子计算
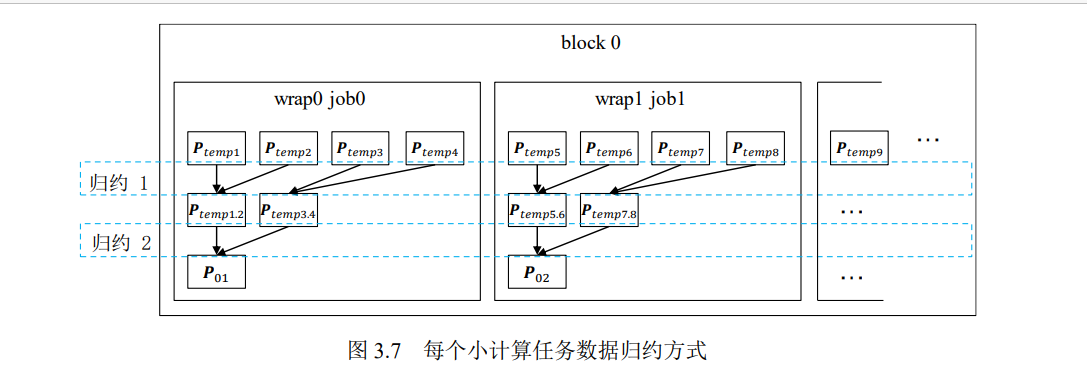
最后两轮访存的跨度大,只需要执行两轮,——> 访存不连续 和block内线程数过低
解决方案: 每一个block合并多个小计算任务
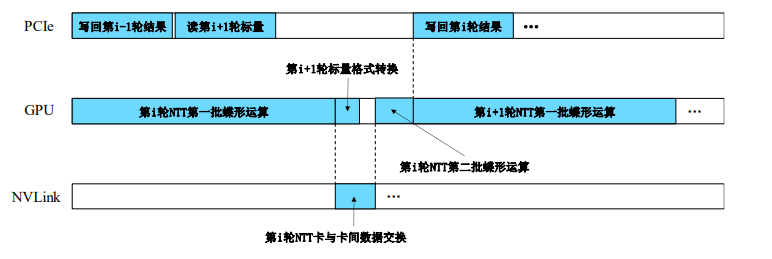
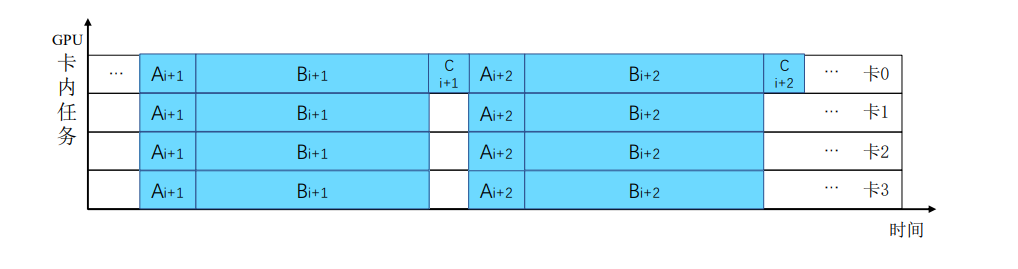
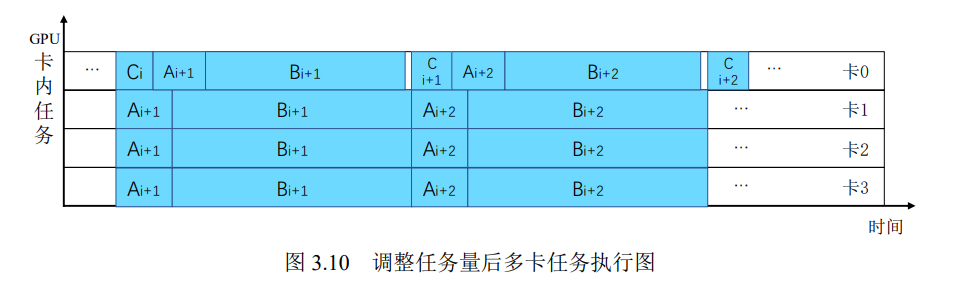
3.计算和通信重叠
MSM 算子
Pippenger 算法的计算热点在桶内点归约阶段,其占了总计算时间的 75%左右,
另外,分桶阶段(包含主存到设备内存拷贝操作)占了总计算时间的 17% 左右,
桶归约和窗口归约占了总计算时间的 8%左右。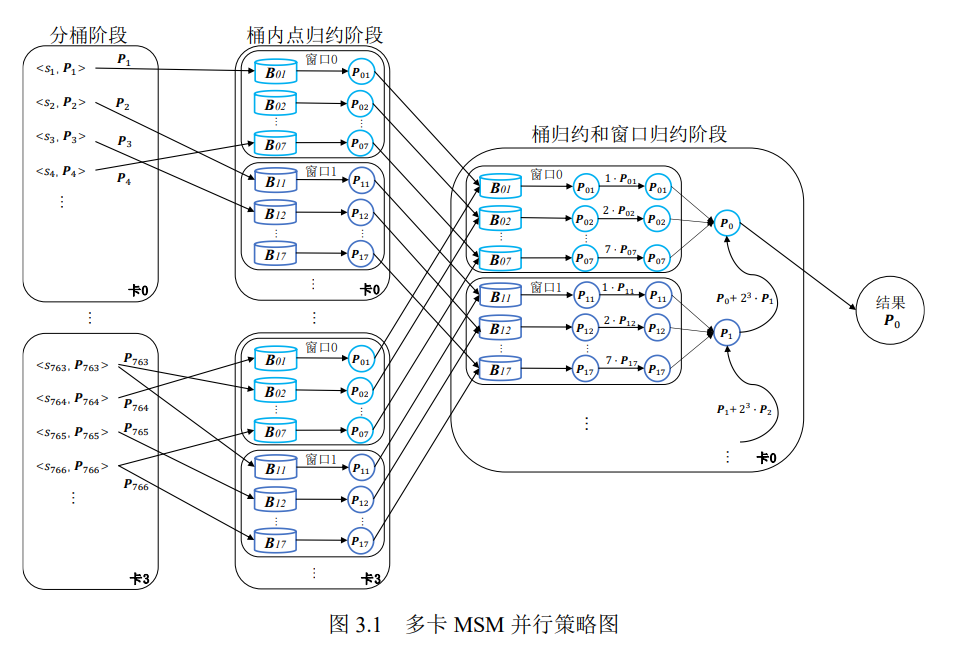
分桶任务
数据的放置方式,标量采取列存储,点采取行存储(仿射坐标系下椭圆曲线每个点包含𝑥和𝑦两个值,这两个值的位数大小为 𝐿(𝐿>= 256)。读取某个点时,该点会被⌈ 𝐿/64 ⌉个线程访问,) 。共同取一个点的一组线程被称为一个tile
桶的摆放
某一个窗口的一个桶如果被访问那么这个桶附近的桶也有很大的概率被访问,那么将桶连续进行放置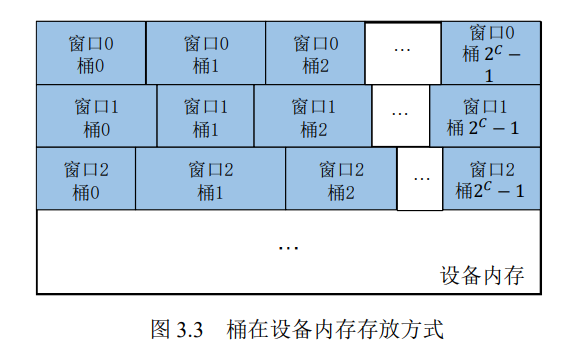
计算和通信重叠
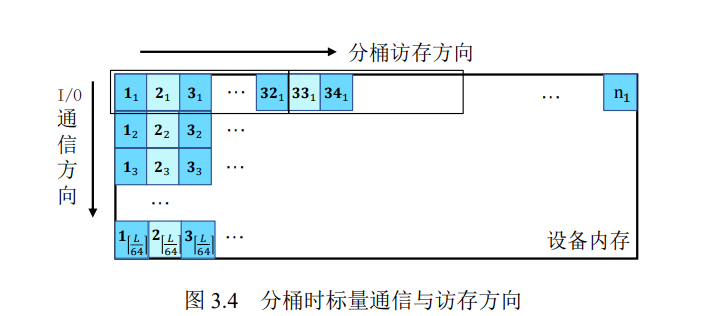
第一行放着标量集内每一个标量的第一个64位无符号整数,后面以此类推。
计算第一个分桶时,进行第二组传输。
高效的分桶策略
竟态条件-》,需要引入 CUDA 原子函数。使用原子函数后, 当两个线程同时写一个统计值时,系统会保证原子性,保证统计结果正确。
桶内规约策略
首先指定一个任务阈值,随后对每个桶的任务大小进 行统计,如果桶内的任务数大于任务阈值,则需要将该计算任务标记为大任务,否则 标记为小任务。
为不同任务给不同的计算资源
Hyper-Q 技术 将多个核函数加载到一个GPU上
小任务导致的线程分束化
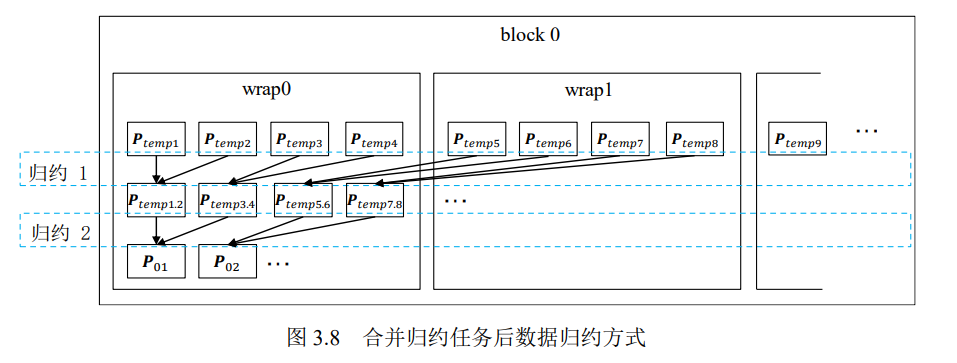
为了解决线程束分化的问题,可以将局部的交错配对归约改成全局的交错配对 归约,将多个小计算任务的中间结果归约操作进行合并。
多卡任务调度优化
MGZKP 提出了适用于零知识证明的多gpu数据划分方案,nvlink替换pcle通信
MGZKP 优化GPU的任务调度和GPU内的任务并行策略,针对访存不连续的问题利用share memory 作为缓存
多gpu的问题:
- 多卡ntt运算的瓶颈在数据划分和传输哈桑,由于算法特性卡与卡之间必须进行数据交换。
- 多卡msm设计存在主存和设备内存传输延迟的问题,进行多卡规约时执行重复计算,卡内任务大小不一致导致的调度困难。
同步数据拷贝
- 定义:同步拷贝意味着主机执行的数据拷贝操作会阻塞,直到数据拷贝完成为止。也就是说,主机的执行会等待这个拷贝操作结束后,才继续往下执行其他代码。
- 优点:
- 代码执行顺序更容易理解和调试,因为所有操作按顺序执行。
- 简化了同步的需求,因为在数据拷贝完成前,代码不会继续执行。
- 缺点:
- 由于拷贝是阻塞的,主机的 CPU 在等待拷贝完成的过程中可能会浪费资源,而不能并行执行其他任务。
异步数据拷贝
- 定义:异步拷贝意味着数据拷贝操作是非阻塞的,主机会立即继续执行后续代码,而不会等待数据
这四点是提升多卡推理性能的关键优化方向,分别从数据处理、并行性、模型效率和资源管理四个维度提升吞吐量和降低延迟。以下是每个优化方向的详细讲解:
1. Batching:批量处理推理请求,充分利用 GPU 的并行计算能力
核心原理
GPU 的计算单元是为批量数据处理设计的。如果一次推理只处理一个请求,会浪费大部分计算资源。通过将多个推理请求合并为一个“批次”,可以充分利用 GPU 的并行能力,提升推理效率。
实现方法
- Batch合并:在推理前,收集多个请求,将它们合并为一个 Tensor 进行处理。
- 例如:多个图片拼接为一个 [batch_size, channels, height, width] 的 Tensor。
- 自动批量工具:
- 使用深度学习框架的内置工具,如 PyTorch 的
torch.utils.data.DataLoader或 TensorRT 的批处理接口。
- 使用深度学习框架的内置工具,如 PyTorch 的
优化点
- 批量大小选择:
- 批次过小:GPU 资源利用不足。
- 批次过大:会增加推理延迟,或导致显存不足。
- 通常根据 GPU 的显存容量和应用的延迟要求调节批次大小。
- 动态批量:
- 使用动态批次机制,根据当前请求队列自动调整批量大小。
2. 多流并行:利用 CUDA Streams 提高多请求的吞吐率
核心原理
GPU 支持多个 CUDA Stream,通过将计算任务分配到不同的 Stream,可以实现不同请求的并行处理,避免单一 Stream 的等待延迟。
实现方法
- 定义多个 Stream:
- 在 PyTorch 中,可以使用
torch.cuda.Stream()创建多个 CUDA Stream。
- 在 PyTorch 中,可以使用
- 请求分配:
- 将不同推理请求分配到不同 Stream 中,让它们并行执行。
- 异步执行:
- 利用异步操作(如
torch.cuda.synchronize())协调任务完成。
- 利用异步操作(如
优化点
- 任务分配策略:
- 可以通过轮询或负载均衡算法将推理请求分配到不同 Stream。
- 同步点设置:
- 确保必要的同步,例如 GPU 到 CPU 的结果拷贝。
3. 模型优化:使用 TensorRT、ONNX 等工具对模型进行量化或剪枝
核心原理
通过对模型进行优化(如量化、剪枝、张量重排等),减少计算复杂度和内存需求,从而提升推理效率。
优化方法
- 量化(Quantization):
- 将模型参数从 FP32 转换为 FP16 或 INT8 格式,减少内存占用和计算量。
- 工具:TensorRT、ONNX Runtime、PyTorch 的
torch.quantization模块。
- 模型剪枝(Pruning):
- 去掉不重要的网络连接或神经元,减小模型规模。
- 工具:DeepSpeed、SparseML。
- 算子融合:
- 合并多个算子为一个高效算子,减少内存拷贝和冗余计算。
- 工具:ONNX Graph Optimizer、TensorRT。
- TensorRT 加速:
- TensorRT 是 NVIDIA 专为 GPU 推理设计的优化框架,可大幅提升模型推理性能。
优化点
- 量化前的校准:
- 在 INT8 量化前,使用校准数据评估精度损失。
- 剪枝后的再训练:
- 剪枝可能影响模型性能,再训练可弥补性能下降。
- 推理框架选择:
- 优先选择专门优化的推理框架,如 TensorRT 或 ONNX Runtime。


- 本文作者: Wynne Yin
- 本文链接: https://wynneyin.github.io/2024/12/14/多卡GPU加速ZKP/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!