

说明:这篇博客基于我的论文 TetrisZK: A multi-GPU Zero-Knowledge Proof Framework with Two-Dimensional Parallelism and Memory-Aware Scheduling 整理而成,面向对系统与加速感兴趣的读者。文中图片位置先用占位符标注,后续可替换为论文中的原图或重绘版本。
论文来源:
1. 为什么“多 GPU + ZKP”并不等于“更快”?
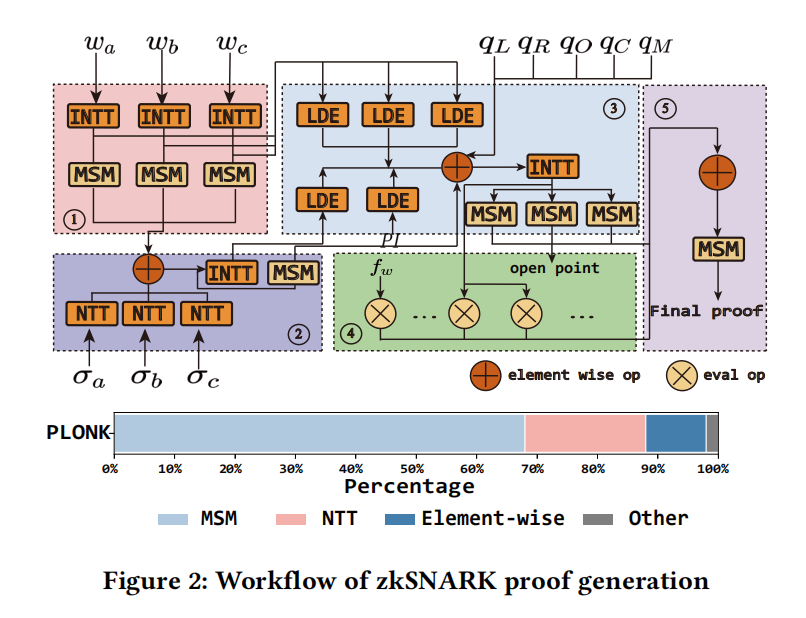
零知识证明(ZKP)让证明者在不泄露秘密见证 w 的前提下,向验证者证明某个断言成立。zkSNARK 由于证明短、验证快、非交互等特性,在区块链、隐私认证等场景里已经相当常见。问题在于:证明生成(proving)非常重,即使使用 GPU 加速,端到端生成一个证明也可能需要分钟级时间。
很多工作把注意力放在两个“硬核算子”上:
- NTT(数论变换):类似 FFT,但在有限域上做,访存步幅大、缓存局部性差。
- MSM(多标量乘):椭圆曲线点的加法/倍点反复组合,算术代价高。
于是直觉上,我们会说:既然单 GPU 慢,那就把 NTT/MSM 扔到多 GPU 上跑,不就快了吗?
现实是:端到端(end-to-end)证明生成是一条很长的流水线,除了 NTT/MSM,还有大量 element-wise(逐元素)运算、数据重排、评估/约束组合等。多 GPU 的策略如果“只盯热点”或“盲目全分布”,都会踩坑。
两种常见但不理想的策略
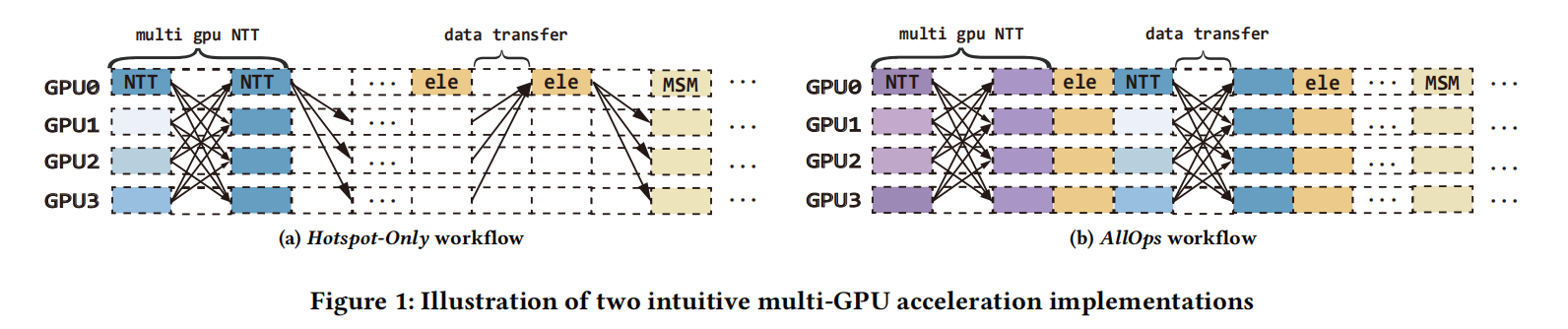
策略 A:Hotspot-Only(只加速热点)
只把 NTT/MSM 扔到多 GPU 上,其他阶段仍集中在单 GPU。这样会带来两个问题:
- element-wise 阶段并非完全可忽略;根据 Amdahl 定律,它会限制整体加速上限。
- 更致命的是:element-wise 阶段往往是显存容量瓶颈(需要同时保留很多中间多项式),把它们堆在一张卡上会触发频繁 offload(主机-设备来回搬运)。
策略 B:AllOps(所有算子都平均撒到所有 GPU)
每一步都跨所有 GPU 分摊计算。看起来“利用率”会更高,但会引入巨大的跨 GPU 通信:
- 像 NTT 这类步幅访问/转置需求强的算子,会频繁触发 all-to-all 交换,通信开销可能吞掉并行收益。

在我们论文的初步实验中(4 张 PCIe GPU),Hotspot-Only 的平均 GPU 利用率只有 16.9%,AllOps 提高到 42.2%,但二者都被 数据传输拖累(时间占比可达 50% 左右)。
这带来一个系统层面的核心问题:
多 GPU 的关键不是“并行越多越好”,而是要为每个算子选择合适的并行粒度,并让显存与通信共同受控。
2. TetrisZK:像玩俄罗斯方块一样“摆放”算子
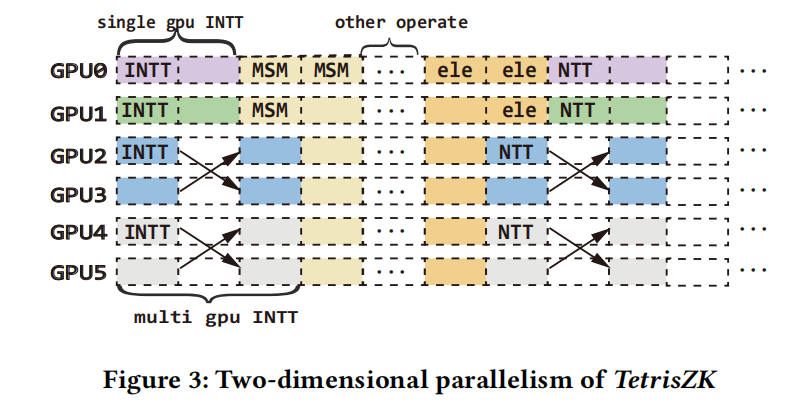
我们提出的框架叫 TetrisZK。名字灵感来自俄罗斯方块:在时间轴 × GPU 轴的二维平面上,算子像不同形状的块,目标是尽量减少“气泡”——也就是通信空洞和 GPU 空转。
TetrisZK 的核心由三部分组成:
- 二维并行(Two-Dimensional Parallelism):把并行从“一个维度”扩展为“跨算子 + 算子内”两种维度的组合。
- 显存感知调度(Memory-Aware Scheduling):把“显存均衡”放到比“纯算力扩展”更优先的位置,避免一张卡爆显存、其他卡闲着。
- 以算换传(Computation-over-Communication, CoC):当通信比计算更贵时,宁可在本地重复计算,也别跨卡搬数据。
下面我用更“系统研究者”的视角,把这三点展开讲清楚。
3. 二维并行:跨算子并行 + 算子内并行,按需组合
3.1 跨算子并行(Inter-operation)
zkSNARK 的证明生成可以抽象为一个 DAG(有向无环图),不同 round 之间、同一 round 内都有依赖关系。关键观察是:不是所有算子都严格串行。比如某些 round 里存在多个彼此独立的 INTT/NTT,可以分别放到不同 GPU 上并行跑,从而减少跨卡同步和 all-to-all。
3.2 算子内并行(Intra-operation)
当计算图缺少足够多的独立任务时,仅靠跨算子并行会导致 GPU 闲置。这时可以把单个算子(如某个 NTT)拆分到多张 GPU 上跑,换取更低延迟、更高利用率。另一个收益是:把大变量分片到多 GPU,从而聚合显存容量,避免 OOM 或 offload。
这两种并行方式是可组合的:比如在某个 round 里,既可以并行跑多个 NTT(跨算子),又可以把其中一个 NTT 再拆到两张卡上(算子内),从而尽量“填满”所有 GPU。

4. 显存感知调度:先别急着加速,先别 OOM
多 GPU 证明生成里,一个容易被低估的事实是:
很多阶段并不是 compute-bound,而是 memory-capacity-bound。
也就是说,瓶颈先是“能不能放得下”,其次才是“算得快不快”。
TetrisZK 在调度时,会把变量分为两类并采取不同策略:
4.1 小而常用:复制(replicate)更划算
例如:
- NTT 的 twiddle factor 表
- MSM 的结构化参考串(SRS)等只读常量
它们体积不大但访问频繁。我们选择在初始化阶段每张 GPU 各放一份,之后所有 kernel 都本地读取,减少跨卡通信。
4.2 大而“同时驻留”:分片(shard)更安全
很多 round(特别是包含大量 element-wise 的阶段)会同时 materialize 很多中间多项式,总尺寸可能超过单卡显存。此时“把算子拆到多卡”的主要目的不一定是更快,而是把显存拼起来,避免 offload/抖动。
此外,TetrisZK 会尽量保持 producer-consumer locality:中间结果留在生成它的 GPU 上,直到被消费,减少无谓搬运。
5. 以算换传:当 PCIe 太慢时,就“别传了,重算吧”
在多 GPU 系统里,通信(尤其是 PCIe)往往比你想象的更贵。ZKP 流水线里存在大量“计算便宜、数据很大”的操作,跨卡搬一次数据的代价可能超过本地再算一遍。
TetrisZK 的 CoC(Computation-over-Communication) 思路就是:
- 如果某个中间量从别的 GPU 传过来很贵,
- 而在本地重新计算它并不贵,
- 那就选择 recompute,让数据留在本地,减少 PCIe 压力。

直觉上这像是在“浪费算力”,但在通信瓶颈场景下,它反而能提高整体吞吐与 GPU 利用率。论文的实验也显示:在大规模问题上,CoC 能显著降低 transfer time,并带来明显端到端收益。
6. 自动生成执行计划:从“手工调参”走向“可迁移的系统”
如果你做过多 GPU 优化,会非常熟悉一个痛点:
手工 tune 的最优计划往往是“脆弱的”——换个电路规模、换个实现细节、甚至多一个多项式输入,都可能推翻之前的最佳策略。
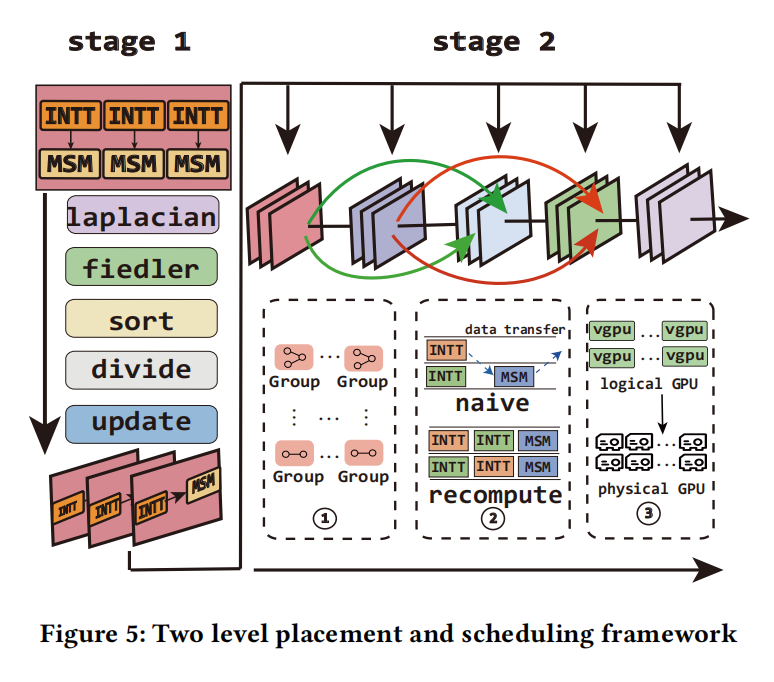
因此 TetrisZK 的另一个重点是:自动生成多 GPU 计划。整体思路是把证明生成抽象为 DAG,然后通过“两级放置”来降低求解难度与提高可移植性。

6.1 第一步:图划分(Graph Partitioning)
直接在完整 DAG 上做 ILP 会非常大、不可用。我们先对每个 round 的子图做划分,把强依赖的算子聚成一个 group,弱依赖的 group 尽量分开,从而降低 ILP 规模。实现上使用了谱划分(spectral bisection):构造 Laplacian,计算 Fiedler vector,并用 sweep cut 找到更优切分。
6.2 第二步:在“虚拟 GPU”(vGPU)上做 ILP 调度
划分得到的 group 会被放置到一组 vGPU 上(vGPU 数量可以独立于物理 GPU 数量)。目标函数综合考虑:
- 纯计算时间
- 跨设备依赖的通信成本 vs 重算成本(transfer/recompute 二选一)
- round 内负载均衡(避免 straggler)
6.3 第三步:把 vGPU 映射到物理 GPU
最后再根据依赖关系与物理 GPU 的负载窗口,用成本模型把 vGPU 映射到具体 GPU。一个 vGPU 可能跨多张物理卡,多个 vGPU 也可能共享一张物理卡——本质上是在“算力、显存、通信”之间做更灵活的折中。
7. 实验结果:端到端更快、利用率更高
我们在 8 张 PCIe 4.0×16 的 RTX 4090 上评估了 TetrisZK(Ubuntu 22.04,CUDA Runtime 12.6)。
7.1 端到端 proving 时间(摘自论文 Table 1)
下表是论文里端到端 proving 时间(单位:秒)的核心结果概括(便于博客阅读,我把它整理成 Markdown 表格;你也可以直接替换成论文表格截图)。
| 电路规模 | 1 GPU (sppark) | Hotspot-Only | AllOps | TetrisZK | TetrisZK / AllOps |
|---|---|---|---|---|---|
| 2^20 | 1.09 | 0.97 | 1.30 | 0.71 | 1.83× |
| 2^22 | 11.72 | 4.81 | 1.85 | 1.21 | 1.53× |
| 2^24 | 330.61 | 103.91 | 8.73 | 5.27 | 1.66× |
| 2^26 | N/A (OOM) | 386.52 | 34.91 | 21.13 | 1.64× |
这些结果反映了两点:
- 盲目 AllOps 在小规模(2^20)甚至会比 1 GPU 更慢(通信吞噬收益)。
- TetrisZK 在不同规模下更稳定地实现端到端收益,并在大规模下还能避免单卡 OOM。
从全文统计上看,TetrisZK 相比当时的多 GPU 基线实现,平均 1.64× 加速,并把 GPU 利用率从 42.2% 提升到 89.1%。
7.2 利用率与拆解分析
论文里还分析了 GPU 数量变化时的平均利用率趋势,以及各项优化对 transfer time 的贡献:
- 仅用二维并行(2D-Only)就能减少一些不必要的通信;
- 加上显存感知(2D-Only + Mem-Aware)在大规模时能显著降低 transfer;
- 再启用 CoC(以算换传)在最大规模(2^26)能把 transfer time 压到原来的约 1/2.98。


8. 我从这项工作里学到的几条“系统经验”
如果你也在做多 GPU 系统/加速器系统,我觉得 TetrisZK 有三条经验值得迁移:
端到端优化要敢于挑战“热点思维”:
在复杂流水线里,热点之外的阶段可能因为显存与依赖结构而变成“隐藏瓶颈”。显存均衡不是附加项,而是调度的一等公民:
只按算力/算子时间来做分配,往往会在真实系统里被 OOM/offload 打回原形。以算换传是一种“系统理性”:
在 PCIe 等互联条件下,重算可能比搬运更经济,尤其是当下游会多次复用中间量时。
9. 可能的后续方向
最后也简单谈谈我认为可以继续探索的方向(不一定在论文里都展开):
- 更强互联(NVLink / NVSwitch)下的策略变化:通信代价变了,CoC 的阈值和 ILP 的权重也应随之调整。
- 在线自适应与鲁棒性:对不同电路、不同数据规模,如何减少 profiling 成本,做更“自动驾驶”的调度。
- 扩展到更多 ZKP 工作负载:除 PLONK 类工作流外,其他协议/变体是否同样受益,以及算子集合变化后的可迁移性。


- 本文作者: Wynne Yin
- 本文链接: https://wynneyin.github.io/2026/02/25/TetrisZK_blog/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!